 Batoi Corporate Office
Batoi Corporate Office
Supervised Machine Learning is a subfield of machine learning that uses labeled training data to learn, just like humans learn from examples. In this blog post, we’ll introduce you to some of the concepts and terminologies concerning supervised machine learning, and we’ll have a look at an example that illustrates supervised learning.
Let’s start with what supervised learning is. It is a machine learning technique that involves training a model on a set of example pairs of input data and desired output data to produce a model that can, given new input data, produce accurate output.
To put it mathematically, Supervised machine learning is based on the concept of a function that maps from an input variable or feature vector X to an output variable Y, which we may hope to predict given an observation about X. These functions are generally constructed by optimizing an objective function (cost function) to select the best mapping. The functions are also called "models" or "classifiers" and can be used for prediction, smoothing, and data compression, among other things. Supervised learning is the most widely used type of machine learning used in various applications, including computer vision, speech recognition, natural language processing, social network filtering, machine translation, bioinformatics, and drug design.
There are numerous supervised learning algorithms out there, among which the most widely used are logistic regression, decision tree, support vector machine (SVM), k-nearest neighbor, Naïve Bayes algorithm, artificial neural network (ANN), multilayer perceptron (MLP), feedforward neural network (FFNN), and clustering algorithms.
Supervised Machine Learning in Action
A supervised machine learning model learns from the data you provide. The model is trained on the data set and tested with test data. A feature selection algorithm is applied to find which features are most important for making predictions about new data. Features that are no longer important drop off from being selected by the algorithm. These features are then used to train and test the model repeatedly, each time refining its accuracy on the training data set.
The following figure shows how a supervised machine learning model learns from training data:
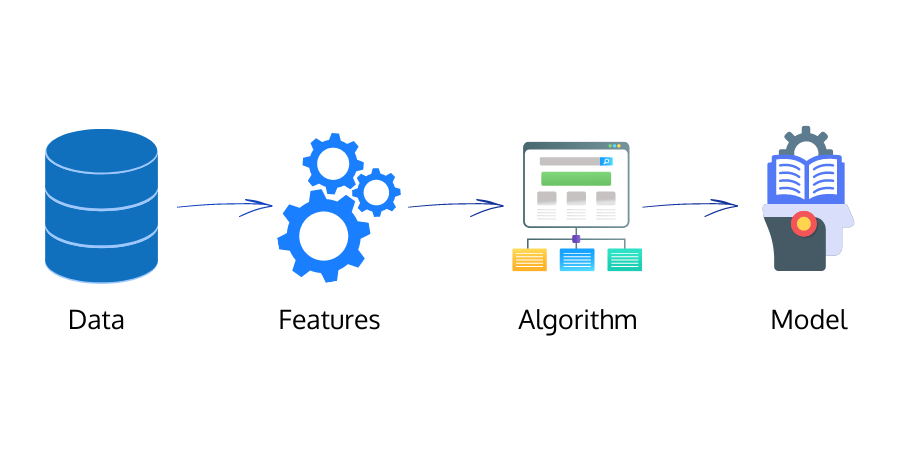
Every time the model gives an output, the output is matched with the actual label. The error that the model makes is calculated using the cost function. The model uses this error data to learn and increase its accuracy. This loop goes on until the model attains high accuracy.
Classification vs. Regression Problems in Supervised Learning
The two main uses of supervised machine learning algorithms are classification and regression problems. In classification problems, the output is one of a finite number of categories. In regression problems, the output is typically a real-valued quantity. For example, in image recognition, which is a classification problem, the input is an image, and the output is the image's category (e.g., "cat", "dog", etc.). While predicting how a company’s stock prices will behave, which is a well-known regression problem, the output is continuous real value.
The supervised learning methods for classification and regression are the same. A target variable y is being predicted from a set of features X. The machine learning algorithm learns a mapping function f(X)->y. The difference here lies in the nature of the target variable and the range of values it takes on.
Many machine learning algorithms can be used for regression tasks, including support vector machines and k-nearest neighbors; for classification tasks, the most popular algorithms include logistic regression and neural networks.
Application of Supervised Machine Learning
Supervised machine learning is widely used in various applications such as:
- fraud detection,
- marketing,
- recommendation engines, and
- text mining
Supervised algorithms are commonly used in predictive modeling problems, especially when a large amount of training data is available. Supervised algorithms can be seen as extensions of simpler classification algorithms (like decision trees) to more complex classification problems. They require that the input features be known and fixed, whereas if features are unknown or fixed, then unsupervised algorithms are preferred. Supervised algorithms are commonly used for prediction and estimation problems, such as predicting blood pressure from patient age, sex, and weight.
Pros and Cons of Supervised Machine Learning
Supervised learning has a lot of advantages. It's easy to find training data, you can use the model to predict new data, and the model itself is relatively simple to build. The performance of the model also optimizes with experience.
What are the disadvantages? First, it requires labeled training data. If you're trying to classify images of different types of dogs, you need lots of pictures of each dog taken in different situations and lighting conditions. Second, it requires a lot of training data. If you're trying to recognize different breeds of dogs, you need enough pictures that represent each breed under various conditions. Finally, it doesn't always perform as well as unsupervised learning.
The strength of supervised machine learning is that we can interpret data by applying what we know to be true. The weakness is that it relies upon large amounts of data and the human interpretations that leverage it. In short, this machine learning algorithm is limited because we are a part of the equation, and therefore, it is ultimately subjective.